A Lightweight Approach To Implement Secure Software Development LifeCycle (Secure SDLC)
Introduction
Secure SDLC is an integral part of any Product Security program. It enables organizations to be successful in their ProdSec maturity journey. In this post, I will try to disect it into the different activities that it comprises of and how to reasonably go about implementing them as a founding ProdSec engineer. If you have landed on this post directly, I recommend giving my previous 2 posts a read - Building a Product Security program from scratch and Product Security Roadmap. Let's get started!
What is Secure SDLC and why should you care about it?
As engineers, we should be familiar with Software Development Life Cycle (SDLC).
At a high level, Secure SDLC is basically an extension of the SDLC. You can think of it as a collection of best practices that allows organizations to reduce the number & severity of security vulnerabilities discovered along with a reduction in the development cost (of fixing those vulnerabilities) proactively earlier in the development phase as opposed to once the software is deployed in production.
In other words, it enables an org to effectively discover, manage and reduce the overall business risks to itself and its customers.
Implementing a Secure SDLC program and rolling it out across the entire org can take months, if not years. That is something you most likely won't have the luxury of as the founding ProdSec engineer and therefore a lightweight approach to this is likely in order. The way I tend to think about it is to go about implementing it in phases - crawl, walk and run. I will give a high level overview of each phase below and then go into the details of the activities subsequently within each phase. The focus will primarily be on the crawl phase. The walk and run phases are not going to be well defined for now.
The Crawl Phase
Think of this like the quintessential activities you could/should be doing as a founding ProdSec engineer in your org for maturing your ProdSec program. In the table below, you will find a rough breakdown of the Secure SDLC activities paired along with the SDLC phase, the input(s), output(s) and a brief explanation of the ROI of doing it. After that, I will briefly cover each of these activities in more details.
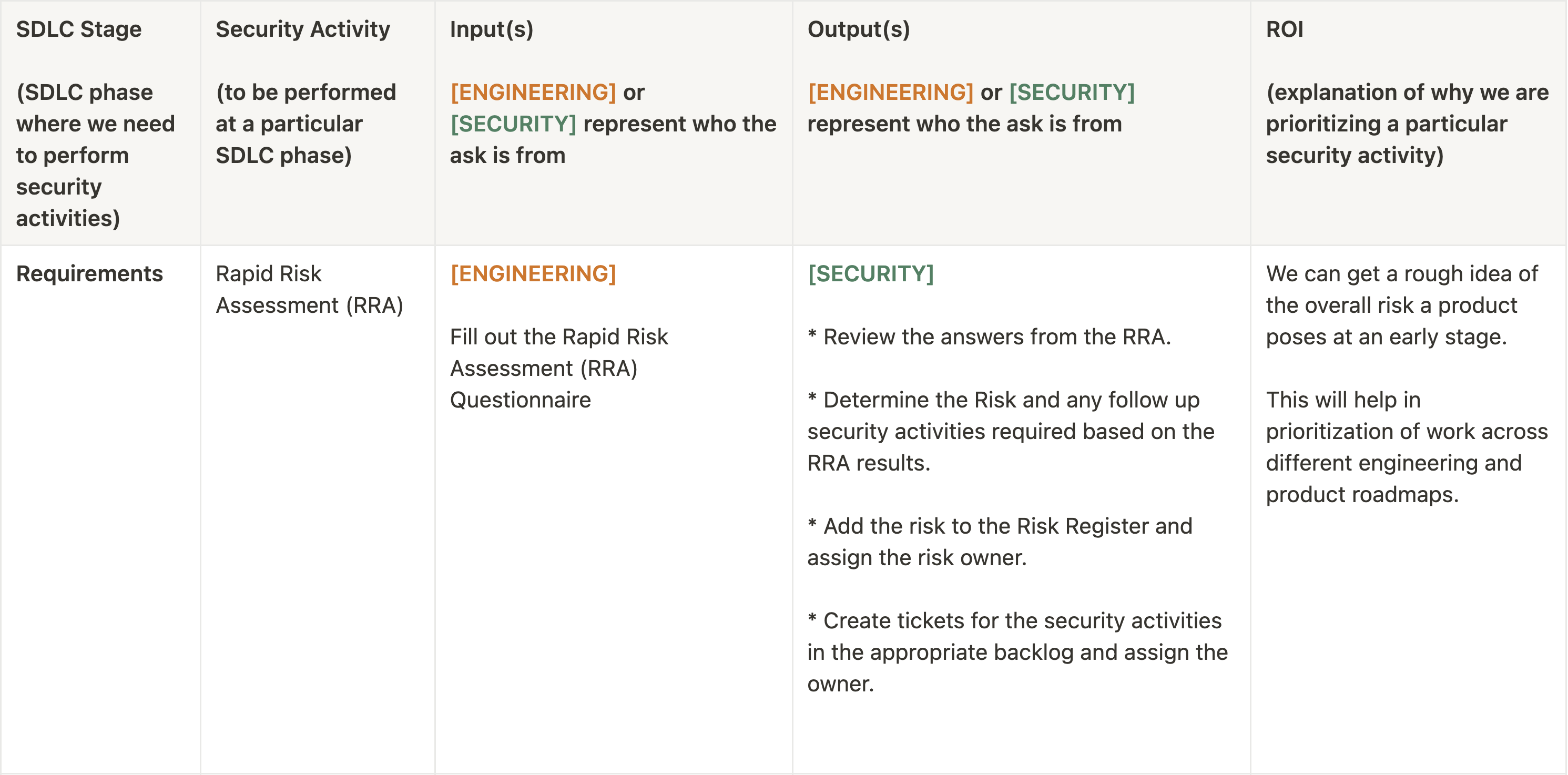


Next, let's dive into some of the details of these activities.
Rapid Risk Assessment (RRA)
Before we begin to think about designing a system/software, it is prudent we think about its risk profile so that we can prioritize accordingly (based on our risk tolerance levels) since not all activities defined in the SSDLC would be applicable across all software/systems being built in an org.
Also, as the founding ProdSec engineer, you need some sort of visibility into the products/applications that are being built. Remember the saying "You can't protect what you don't know". Along with this visibility, you would also need some sort of a framework to decide whether something needs your attention or not because it is just not possible to secure all products with the same rigor and there has to be some sort of risk based prioritization. I believe, a Rapid Risk Assessment aka RRA can help achieve some of these.
A Rapid Risk Assessment or RRA (inspired by Mozilla's RRA, Better Appsec Post and ISACA's model) should ideally be the first activity that is implemented in the SSDLC program. At its core, it is meant to gather some basic information (back of the envelope type estimation(s)) about the type of data that is going to be stored, processed or accessed. In addition to that, there can be other important factors captured as well such as - are the systems exposed on the internet? What is the data classification? So on and so forth. Once you get a rough idea about these, you can likely build some sort of a criteria/framework that will help evaulate the risk that a particular feature/product/application might introduce to an organization.
This is important because it will enable you to ruthlessly prioritize the work that you ought to be doing vs the work you think you should be doing. The outcome from conducting a RRA should be fed into the org Risk Register as well as a list of recommended security activities should be proposed by the security team depending upon the overall Risk Rating. Now, having said that, I believe this is also the most difficult activity to roll out consistently org wide because culture plays a huge role in defining how successful you will be at it.
In my experience, you will really have to understand the engineering culture and drive the adoption of RRAs accordingly. For example, you are going to have to keep asking folks to fill the RRAs until it really seeps in the engineering culture. You are going to have to keep talking about it at All Hands until it becomes second nature. You will have to viciously monitor chatter about new services being introduced and hound the appropriate folks to fill the RRA, if they haven't already done so. It is not going to be easy but if done consistently and repeatedly, you will start seeing results soon.
Criteria for filling a RRA
I hate to say this but you will have to trust your EMs/Sr. Engineers to make an informed judgement call whether something needs a RRA or not. There is no right or wrong answer here. You can provide them guidance but you would have to eventually rely on them to make that decision. You can try to make this a mandatory step in your SDLC before any code gets committed but in my experience, there is often a lot of friction and confusion observed as a result of it.
This is because different teams operate in different ways using different tools and unless you have a consistent way of integrating the RRA across the board, I believe it is not worth spending the time and effort trying to mandate RRAs by means of process. I would rather just repeat myself as much as I can until there comes a point that I don't have to repeat myself again.
You can make the RRA available as a questionnaire form that folks can fill. And, the results are sent directly to the security team. Any project management tools like Asana or Jira can help with this. The guidance that you can provide could look something like below:
When to fill the RRA
- Is the change happening in any endpoints/resolvers/queries/mutations? Is it a CRUD operation?
- Is the change introducing any net new communication with internal or external services?
- Is the change going to deal with any customer data?
- Is it a change in one of the core components that might have direct or indirect dependency on things like Authentication, Authorization, etc.?
- Is the change happening in how Infrastructure is deployed?
When to skip the RRA
- Is it a cosmetic change in the frontend? For example, changing how the footer looks like on the website.
- Is it a static change that doesn’t affect any business logic or data? For example, adding a new option in the services that the org offers.
- Is the change applicable to the frontend primarily with no major changes to the backend code?
What comprises a RRA questionnaire?
Below are some data points you can capture via the RRA questionnaire. Obviously, every org will be different so feel free to take this as a starting point and modify it as needed.
- General Information
- Name of the person filling the RRA
- Team
- Product Name
- Product Description
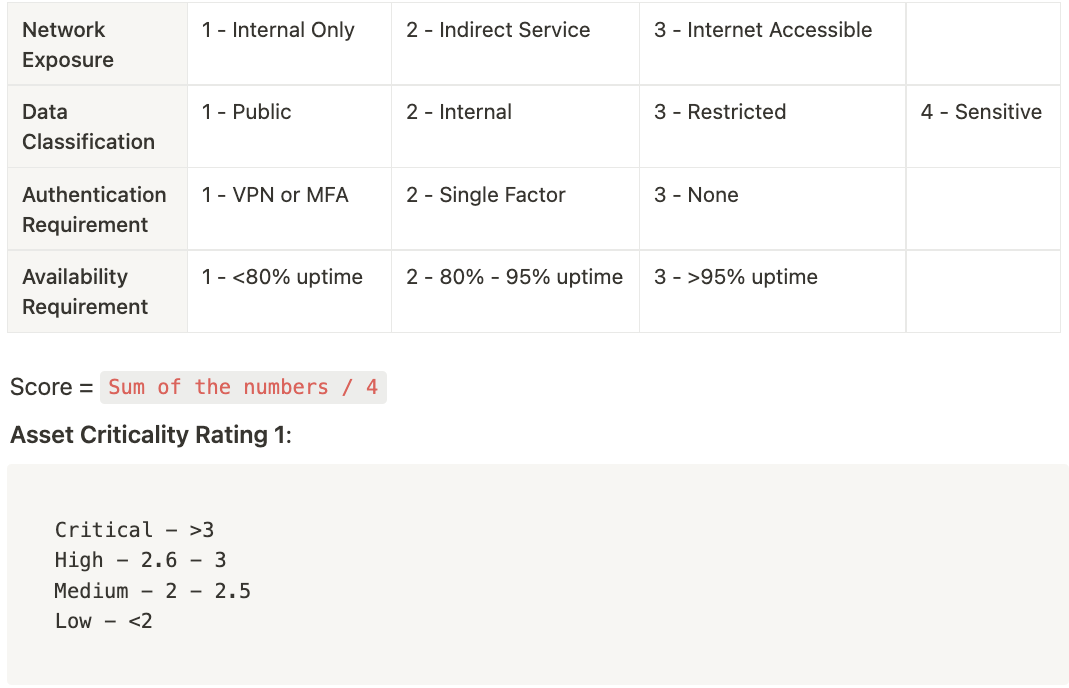
- Network Exposure
- Internal Only
- Internet Accessible
- Indirect Service (Think Kafka queues. They are not accessible on the internet. They are also not meant for internal use only. But, services use Kafka to stream events and as a pub/sub so they would be considered as an indirect service.)
- What is the highest level of data classification for this service/product based on your org's Data Classification policy? Some possible values could be:
- Sensitive
- Restricted
- Internal
- Public
- Authentication Requirement
- VPN or MFA (Multi-Factor Authentication)
- Single Factor
- None
- Availability Requirement
- less than 80% uptime
- 80% - 95% uptime
- greater than 95% uptime
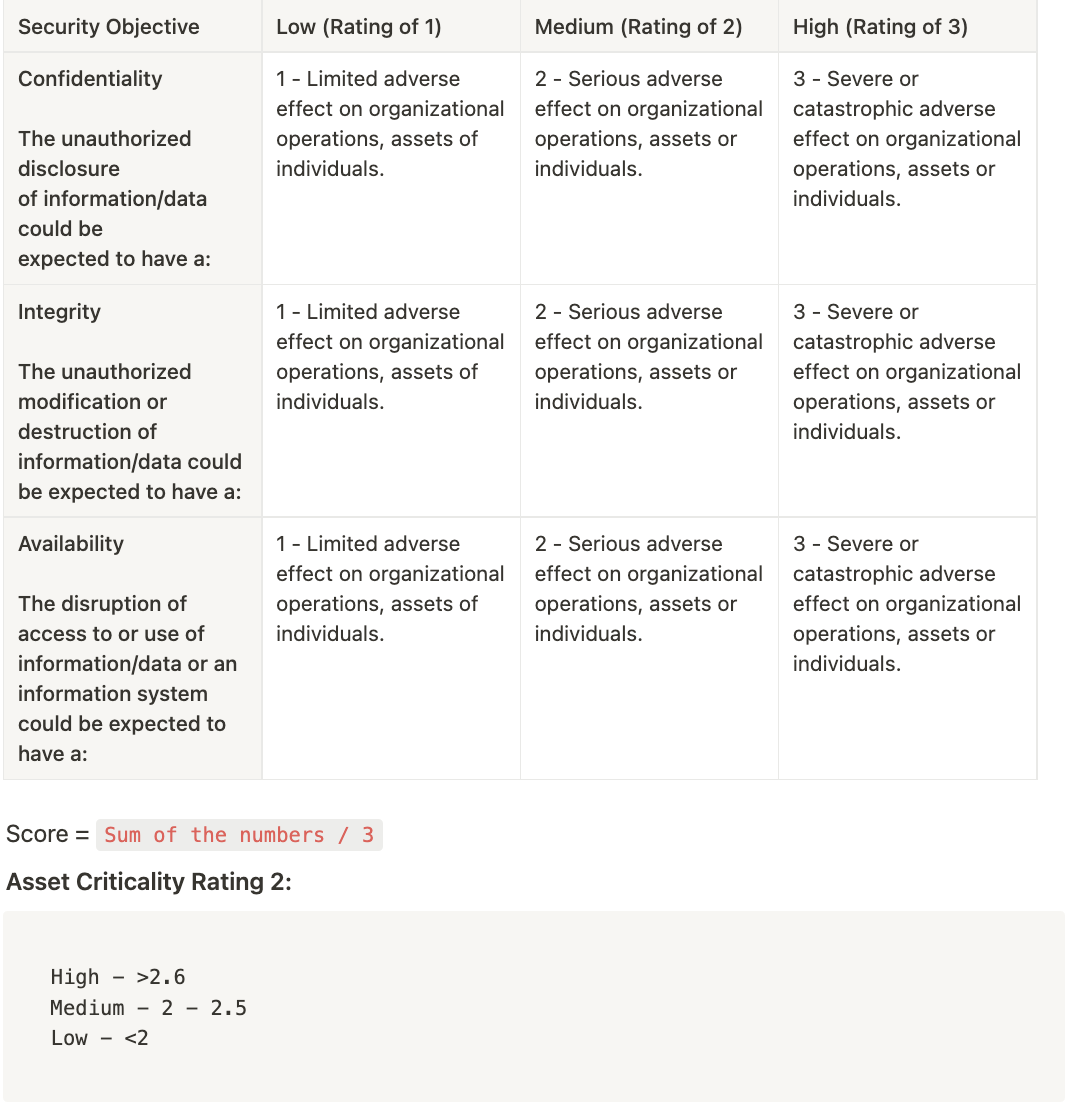
- Confidentiality - The unauthorized disclosure of information/data could be expected to have a:
- 1 - Limited adverse effect on organizational operations, assets of individuals.
- 2 - Serious adverse effect on organizational operations, assets or individuals.
- 3 - Severe or catastrophic adverse effect on organizational operations, assets or individuals.
- Integrity - The unauthorized modification or destruction of information/data could be expected to have a:
- 1 - Limited adverse effect on organizational operations, assets of individuals.
- 2 - Serious adverse effect on organizational operations, assets or individuals.
- 3 - Severe or catastrophic adverse effect on organizational operations, assets or individuals.
- Availability - The disruption of access to or use of information/data or an information system could be expected to have a:
- 1 - Limited adverse effect on organizational operations, assets of individuals.
- 2 - Serious adverse effect on organizational operations, assets or individuals.
- 3 - Severe or catastrophic adverse effect on organizational operations, assets or individuals.
How to go about calculating a Risk Rating from the RRA answers?
Below is just my opinion. I am aware that it might not work for your organization. I am also aware that it is not based on any scientific framework so might not be accurate. But, it has worked reasonably well for me to inform whether something is critical enough for me to pay attention or not - goal of the RRA. I hope at the very least, it inspires you to build something more concrete.
First, let's calculate the asset criticality rating (Let us refer to this as ACR1) from the data classification & technical requirements answers received:
Next, let's calculate the asset criticality rating (Let us refer to this as ACR2) from the loss of Confidentiality, Integrity and Availability answers received:
Once we have both the ACR1 and ACR2, we could come up with an overall Risk Rating based on the table below (similar to how you would calculate Risk based on Likelihood and Impact):
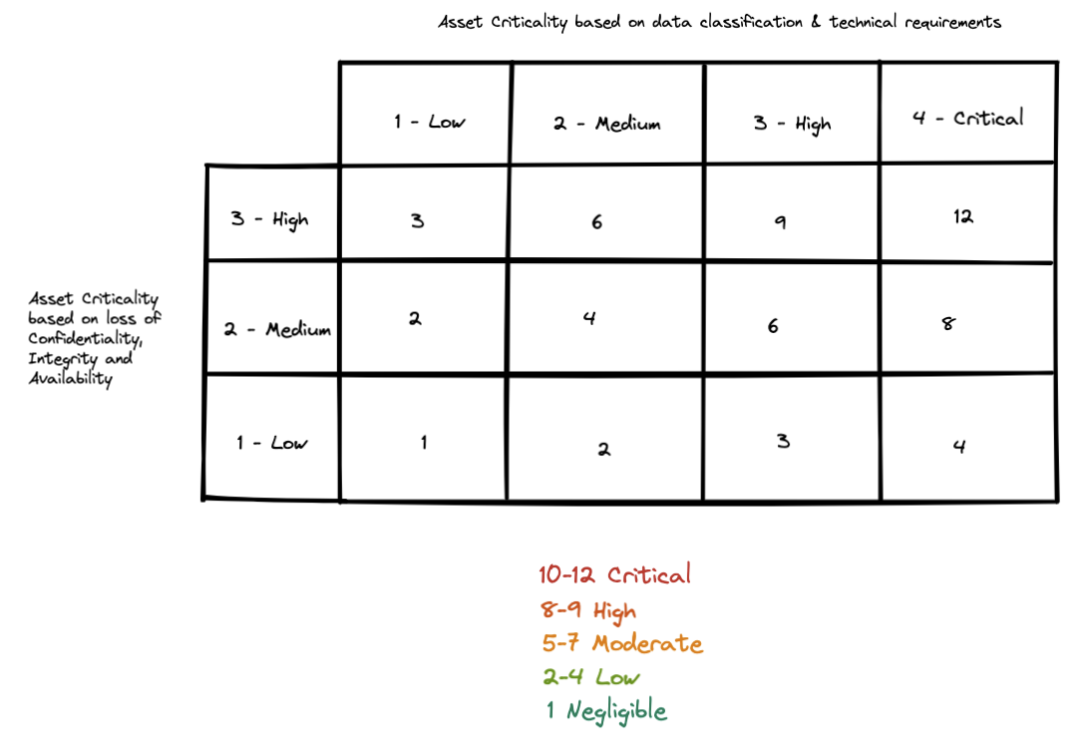
Finally, once you have the overall Risk Rating, you could be determining what additional SSDLC activities could be performed:
- If the Risk Rating is
NegligibleorLow, no further action is required. - If the Risk Rating is
Moderate, Tech Design Review is a must. - If the Risk Rating is
High, Tech Design Review and Threat Modeling is a must. - If the Risk Rating is
Critical, Tech Design Review, Threat Modeling and Pentest / Manual Assessment is a must.
You could practically automate this process such that EMs/Sr. Engineers can access the RRA form at a link. They fill the answers and submit. You automatically apply the above framework and calculate the overall Risk Rating. You add it to the Risk Register and create tickets for the required security activities in the appropriate backlog. This way, you have streamlined the intake of work and automated the process of risk based prioritization in a somewhat lightweight manner. You can now focus on tackling only the most important work without getting overwhelmed.
Tech Design / Architecture Review
It is my belief that any tech company should be mandating writing RFCs / Tech Designs / Design Documents. If that's not the case, I would try to work with the appropriate stakeholders to get such a process in place first.
If such a process already exists, the focus should be to bake in some security questions that the engineers are required to fill out when they write these RFCs. These questions would cover areas such as application security controls, network security controls, data security concerns, cloud security controls and incident response measures. Having a DFD (Data Flow Diagram) should be a requirement of such a document as well. The DFD helps a lot with the security architecture review in understanding how different services and components integrate with each other. It helps in understanding the different threat boundaries and will eventually be used in the Threat Modeling step after this.
The main purpose of this process is to gather security specific information while our engineers are already thinking about the technical design of their service/product. Gathering this information by way of asking questions will not only motivate our engineers to proactively think about security implications but will also greatly inform the security team about some of the decisions being made around the design of the implementation and the overall architecture.
This further enables the security team to highlight any potential areas of concern and/or provide security best practice recommendation(s) wherever appropriate. Overall, this is a win-win situation for everybody as it effectively avoids design flaws from being introduced at the design level as opposed to post deployment, thereby saving time and effort to fix the issues as well as keep the developer productivity at a high pace.
Some example questions (not exhaustive):
Authentication
- Are all net-new resources guarded with an authentication strategy?
- Does your service set any cookies or custom headers?
- Does your new service use a standard authentication pattern or a custom pattern?
- If your service depends on a third-party, how does that third party authenticate against the org's services?
Authorization
- Is every authenticated resource in your service limited to a fine-grained set of user roles (RBAC)?
- Does every request fully revalidate authorization details?
- If the service uses JWT, is the JWT properly decoded and validated (signature) to have a known algorithm, a known issuer, audience, etc.? Is the JWT further checked for the appropriate permissions as necessary?
Input Validation / Sanitization
- Does the service take any input from an end user? If it does, are you using any frameworks/libraries to protect against some common injection attacks - Cross-Site Scripting, SQL Injection, etc.
Encryption
- Does the service process any sensitive user/customer information?
- Does the service store any user/customer data? If it does, is it encrypted?
- Does the service store any user/customer data in a database? If it does, is the connection string to the database fetched from a secret manager solution (such as Vault)?
- Does the service implement any encryption / decryption / salting / hashing? If it does, does it use recommended algorithms?
Logging
- Does the service implement logging as per the org's audit logging standard?
Monitoring / Alerting
- Does the service have proper monitoring and alerting in place?
Threat Modeling
One thing I have personally always struggled is to figure out a way to conduct threat modeling on an ongoing continuous basis with your engineering counterparts if you are the founding ProdSec engineer. If you have ideas around this that have been effective, I would love to hear about it!
This is by far my favorite activity/topic in the SSDLC program. Threat Modeling is an activity that can be as simple or as complicated as you want it to be. It is something that has been spoken about at lengths by various well respected industry veterans so I wouldn't go too much into what it is, but what I will do is to walk through an approach that can be highly effective.
Some folks swear by Threat Modeling tools whereas some folks just wing it by starting a conversation with their engineering counterparts and follow the conversation to see where it leads them. As for me, I like a little structure to how I think about things (if you haven't already figured it out yet) so I use the STRIDE framework as my guiding principle but I still very much like to keep it conversational by asking a ton of questions. This approach is very lightweight and seems to work fairly well in my opinion.
The idea here is to develop a general high level understanding of the different boundaries between logical system components, enumerating some potential attack vectors, identifying existing & missing security controls and prioritizing them. The DFD diagram in the tech design document (previous step) could be used as a starting point here.
It is probably worth mentioning that in order to scale the product security team, the engineering teams should ideally be conducting their own threat models with the support and guidance from the security team. But, until the org reaches that level of security maturity, the security team should be the one investing their time and resources in leading the threat modeling sessions and educating the engineering org on how to go about doing threat modeling. This is probably the only sort of security training/education I would recommend spending time on in the beginning. In other words, teaching your engineers how to threat model and think like attackers goes a long way when it comes to security training.
I will try to briefly walk through an example below:
The below diagrams are from this youtube video. Jonathan Marcil is a master at threat modeling and credit should be given where it is due. I am just going to use his example from this talk and hopefully dumb it down. I would highly recommend watching his talk.
Step 1:
Draw the architecture diagram (DFD) in a way that shows the connections between different components. Ideally, if you go from left to right or top to bottom, it is much more visually pleasing without a lot of distractions. Keep this diagram focussed on the core components that are in scope of the threat modeling. Even if they might have other dependencies, it is not necessary to show all of them. Example:
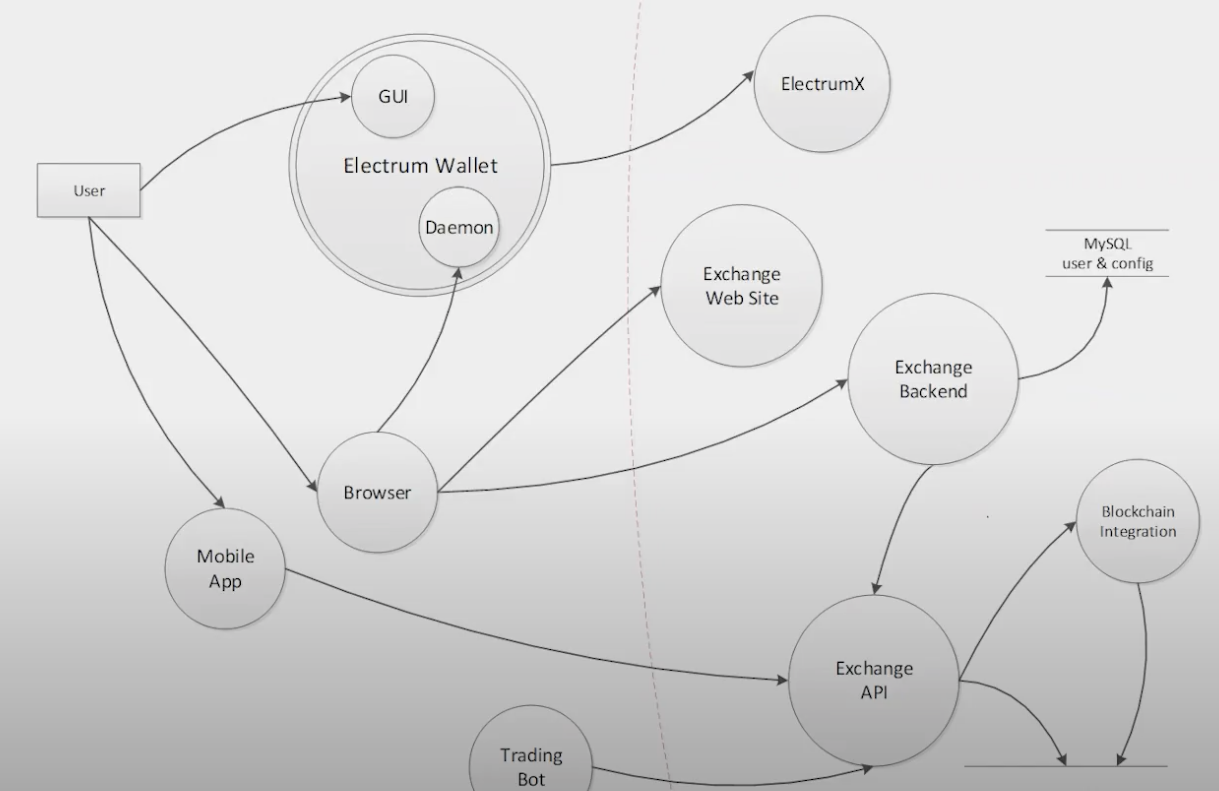
Step 2:
Add information about the protocol between components, tech stacks, and any other necessary information that can help aid the threat modeling process. Example:
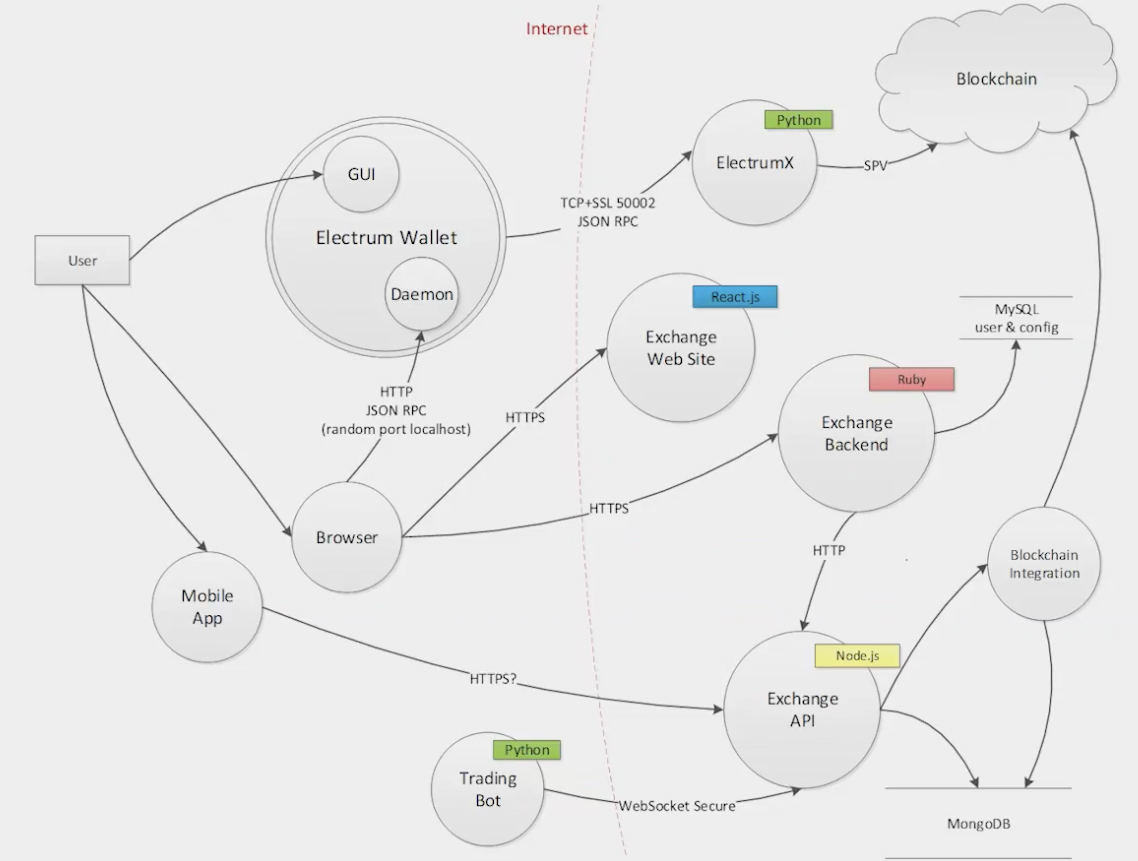
Step 3:
Now, using the STRIDE framework, start brainstorming how a bad actor might potentially try to steal the assets and mark them in the diagram as you discover existing and missing security controls. For example, in the above diagram:
- S (Spoofing) = How is the request from the browser getting authenticated by the Electrum Wallet? If not, mark it and highlight as a missing security control via a legend as shown below. If there is authentication, you don’t have to mark it (to keep the diagram fairly less cluttered). Having said that, you can also choose to highlight it as an existing security control just to keep the positive tone going. Rinse and repeat across all the core components being threat modeled.
- T (Tampering) = How is the integrity of requests being maintained between the electrum wallet and ElectrumX? Is there some kind of a hash/signature based integrity check happening to ensure that the request has not been tampered with?
- R (Repudiation) = Are the requests between components logged? Are they shipped to a central logging server? Do any of the components not have logging enabled?
- I (Information Disclosure) = Is the electrum wallet encrypted at rest?
- D (Denial of Service) = Are there any rate limiting controls on the exchange API to prevent somebody from spamming?
- E (Elevation of Privileges) = With what privileges is the mobile app talking to the Exchange API? Or, in other words, how is the exchange API checking authorization permissions for requests coming from the mobile app?
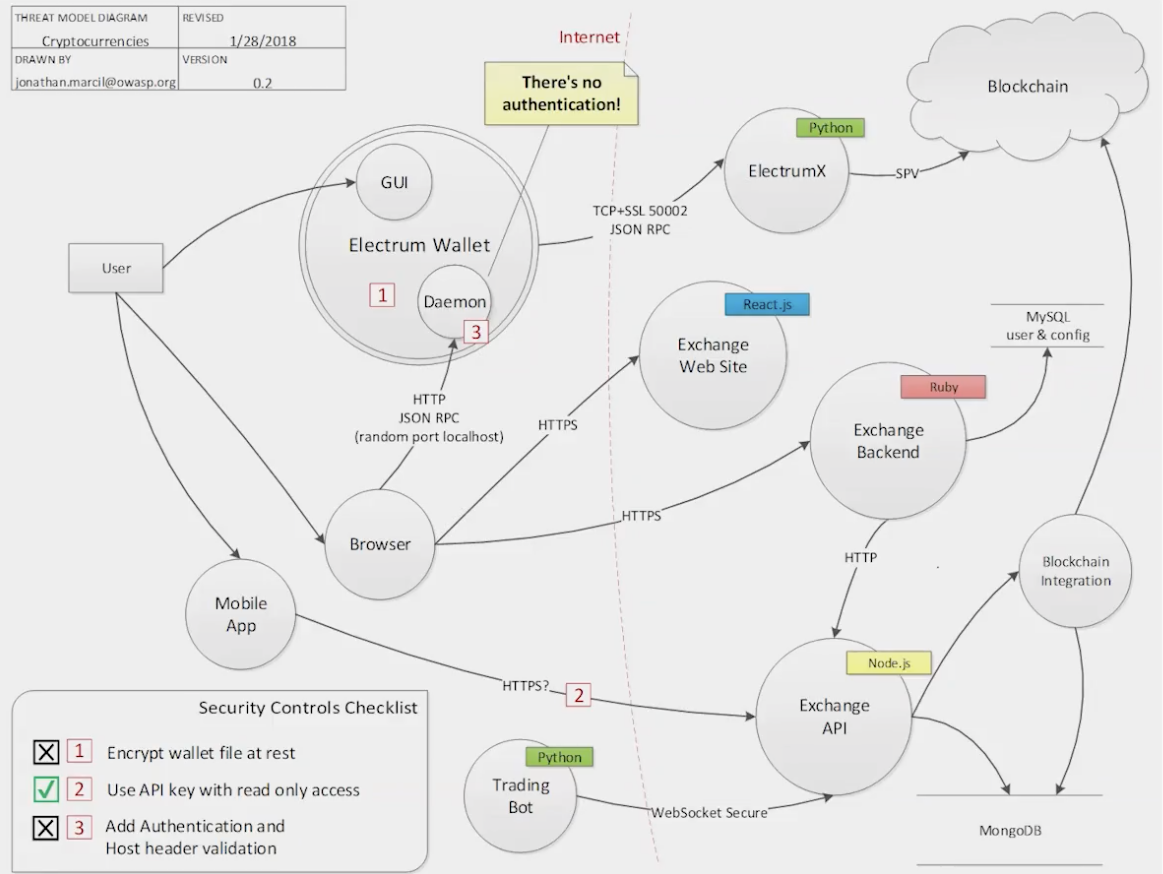
Step 4:
Once you have gone through the entire architecture and have identified some missing security controls, prioritize them by determining the risk (likelihood x impact) and comparing it with the business risk tolerance level, keeping in mind the revenue impact and the level of effort required to mitigate/fix a missing security control.
Static Analysis Security Testing (SAST)
As per Microsoft’s SDL, SAST is “To analyze source code before compiling to validate the use of secure coding policies”. SAST can be used to perform static code reviews as well as detect deviance from secure by default coding standards. The ideal place to integrate SAST scanning would be on every PR across the org's codebase(s) as and when code gets committed. I am a big fan of Semgrep as a SAST tool. The feedback loop for SAST scanning should be relatively quick since you would want to alert the developers of a potential bug as soon as they are trying to commit code to a repo.
The trick here is going to be - how do you balance scanning whilst ensuring engineering toil is at minimum, yet providing value. You could look to roll this out in phases i.e. run a rule ad-hoc, see the results, fine-tune it to a point where you can be absolutely confident it wouldn’t produce any false positive or false negative and only then introduce it on every PR/CICD pipeline in a blocking mode. Semgrep allows us to do this because of its ability to write custom rules. More on this later!
Apart from scanning the application code base, you can also implement Infrastructure as Code (IaC) / Policy as Code scanning as well via your SAST tool. This would make it slightly easier to detect public S3 buckets at the repo level as opposed to detecting once they are already made public.
I won't go too deep into SAST in this post because my next post is going to be all about SAST so stay tuned!
That's it for the Crawl Phase. As the founding ProdSec engineer, if you focus majority of your time in these 4 areas (Rapid Risk Assessment, Tech Design/Architecture Review, Threat Modeling, Static Analysis Security Testing) in the beginning, you will most likely build a rapport with the engineering org and would have made a significant impact in getting started in your ProdSec journey. The walk and run phases mentioned below would naturally come after you have implemented these activities and been doing them for a few months/quarter. I will briefly cover the walk and run phases with more details on them later as we progress through this series.
The Walk Phase
All the activities in the crawl phase are included in the walk phase by default. The activities listed below are in addition to that.
Third Party Dependency Scanning
This entails scanning the codebase(s) for any vulnerabilities in third party dependencies, including, but not limited to, open source libraries. The ideal place to integrate this scan would be on every PR across the codebase(s). You could use something like Dependabot to help you with it. Take a look at this article from the Netskope security team on how to go about it.
Dynamic Analysis Security Testing (DAST)
As per Microsoft’s SDL, DAST is “run-time verification of fully compiled software to test security of fully integrated and running code”. Once software/code is successfully past the PR approval stage and is deployed in a staging environment ready to be tested, you would want to run some kind of a DAST scan against the runtime application in order to detect any potential vulnerabilities.
DAST scans could be integrated in the CICD pipeline such that they are fully automated with the intention of catching low hanging fruits (lack of missing headers or flags) and generic configuration errors that are easy to scan for. For issues that cannot be easily scanned for automatically, we could run a quick DAST assessment manually with the intention of catching potential high priority bugs as identified in the threat model of the particular application in the earlier phases.
The feedback loop for DAST scans would be such that as soon as a PR is issued → CICD kicks in → staging env spins up → DAST runs → results are then sent back.
Penetration Testing
Depending upon the resources available and/or the budget, you could either hire an external consulting company to perform a penetration test on your applications or perform one internally. The goal here should be to focus on what matters the most from a business risk perspective i.e. perform a time boxed black box security assessment focussing on the key areas identified during threat modeling.
The Run Phase
All the activities in the crawl and walk phase are included in the run phase by default. The activities listed below are in addition to that.
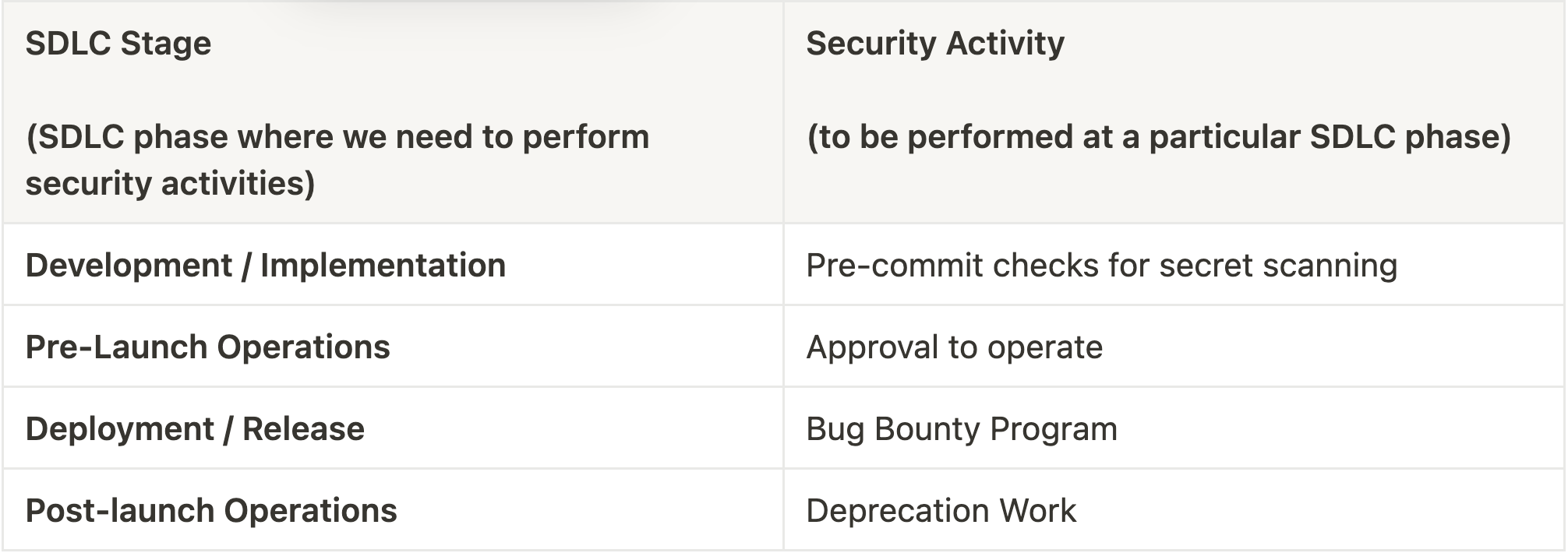
Pre-commit Checks For Secret Scanning
This involves scanning for things like accidentally committing a secret to Github. You would want to catch those even before a commit is made. The ideal place to integrate this scan would be on local developer workstations so that secrets don’t get committed to Github in the first place. Along with that, you can also integrate this as a post commit check but before a PR is approved. This multi layer approach would ensure you have checks in multiple places to catch such mistakes eventually, even if they fail to get caught in one particular place, following the strategy of defense in depth.
Bug Bounty Program
From a business ROI perspective, starting a bug bounty program is a great way to get most of the low hanging fruits reported by security researchers / bug hunters without causing a huge dent in the bank balance. Not only that, you can also create tailored scopes and focus areas with increased incentives and bonuses to attract high quality researchers towards your program and having them discover and report more impactful bugs with real world exploits.
That's it folks! I know this was a lot but hopefully it was all helpful. As always, please reach out to me if you have any questions or if you would like to share your war stories.